论文:iForest: Interpreting Random Forests via Visual Analytics
作者:Xun Zhao, Yanhong Wu, Dik Lun Lee, and Weiwei Cui
发表:IEEE VIS 2018
简介
现已经有了很多对机器学习模型进行可视分析的方法,然而对于随机模型,其缺少有效的可视分析手段,使得该模型难以理解。在现有机器学习模型可视化以及人机交互相关的基础上,设计了一个名为 iForest 的可视化分析系统,可以有效地帮助人们理解随机森林模型。
该系统的主要内容为:特征与预测结果之间的关系;揭露随机森林的工作机理即决策路径;可以提供完整的案例分析
相关工作
随机森林模型是由多颗决策树产生,因此随机森林模型要比一颗决策树复杂的多,且会产生多个预测结果,因此决策树的可视分析手段在随机森林中并不完全适用。因此需要通过了解除了输入输出信息之外,其他的信息来帮助理解随机森林模型。经过总结,可以通过以下三个方面来增加对随机森林模型的理解:
特征分析
即需要知道输入数据中某个特征对最后预测结果的影响和特征的重要程度。
可以用 MDI(Mean Decrease Impurity)来表示特征的重要程度。用 PDP(Mean Decrease Impurity)来表示特征对最后预测结果的影响。
模型简化
由于随机森林模型过于复杂而导致了理解的困难。因此,可以通过综合所有的决策路径并加以分析来达到揭露模型工作机理的目的。
基于案例分析
相似的输入应该有着相似的输出,这有助于提供随机森林的整体图景,例如观察模型性能,检查模型倾向于错误预测的数据类型,或识别特征重要性和影响。
设计目标
基于上文所讲增加理解模型的三个方面,可以对应提出三个设计目标,即:揭露特征和预测结果的关系,背后的工作机理以及提供案例分析
本文基于此,构建了一个 IForest 可视分析系统,并且提出了 2 个具体的使用场景和一个定性的 use study 来说明该系统的有效性。
可视设计
系统整体界面如下所示,由 A、B、C 三个子界面构成。
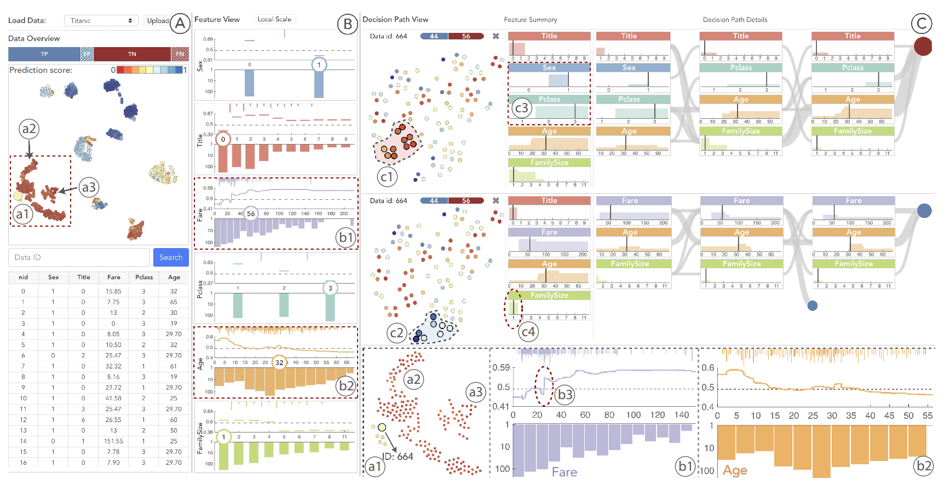
分别为:数据投影视图、特征视图以及决策路径视图。
数据投影视图主要如下所示:
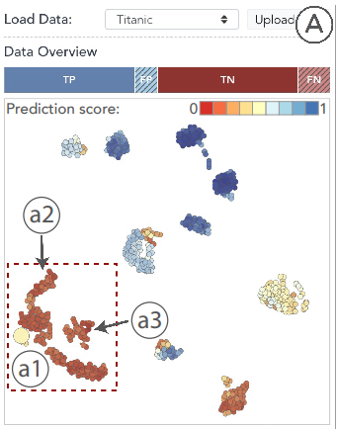 其用 tsne 投影将训练数据集投影到了二维平面,且数据集可以人为加载。投影图中,每个点代表着一个样本点,颜色编码为预测结果的大小,区间为[0-1],由于所用的随机森林模型均为二分类器,因此在本文中,默认使用 0.5 为分割线。预测结果大于 0.5 为正样本,小于 0.5 为负样本。同时使用一个长条矩形代表混淆矩阵。可以选取混淆矩阵查看数据点的真实预测结果。
其用 tsne 投影将训练数据集投影到了二维平面,且数据集可以人为加载。投影图中,每个点代表着一个样本点,颜色编码为预测结果的大小,区间为[0-1],由于所用的随机森林模型均为二分类器,因此在本文中,默认使用 0.5 为分割线。预测结果大于 0.5 为正样本,小于 0.5 为负样本。同时使用一个长条矩形代表混淆矩阵。可以选取混淆矩阵查看数据点的真实预测结果。
通过选取特定的样本点,可以对样本点进行进一步的分析。
特征视图

按照每个特征的基尼系数来进行排序。
例如,图中特征 a 的重要程度就大于特征 b。
每个图,可以分成上下两个部分。
上部分为 PDP 和每个 split point 的分布
其中,PDP 代表该特征对最后结果的影响。
PDP 曲线中,值的计算公式为:
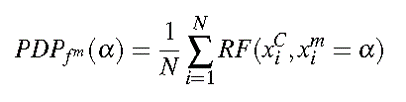 比如,特征 m,输入数据即将特征 m 的值设定为 α,其他不变,改变 α 的值,看最后结果变化。
比如,特征 m,输入数据即将特征 m 的值设定为 α,其他不变,改变 α 的值,看最后结果变化。
下部分为特征值分布
决策路径视图
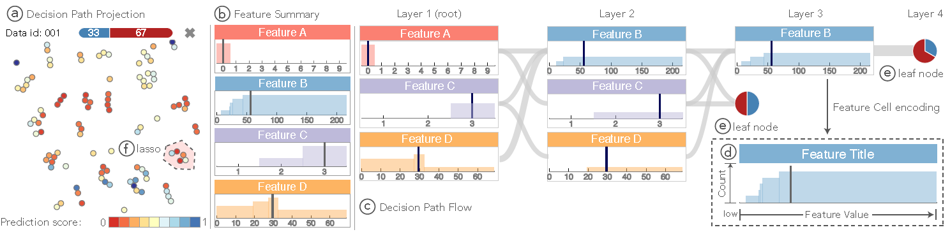
该视图同样由 3 部分组成,a 为随机森林中所有决策路径的 tsne 投影视图,点的颜色同样编码了该路径的预测结果大小。投影图右上角长条编码了正负预测结果的占比。
b 为特征总结图。其由一个个特征细胞构成,每个特征细胞内为该特征值在决策路径中的分布情况。直方图的高度,代表该值在决策路径中出现的次数。其中,灰色的竖直线代表了当前数据点的真是值。
c 图为决策路径流。当在投影视图选取部分决策路径之后,被选中的决策路径会以决策路径流的方式呈现。每个流同样由一个个特征细胞构成。从左到右为从根节点到叶结点的过程。每一层之间的特征细胞由曲线相连,曲线的大小代表着当前流向中包含的决策路径的数量。当决策路径走到叶结点,最后以一个圆形来进行编码。圆形中的颜色和读书分别编码了对应的正负预测结果和占比。
在对决策路径进行投影时,需要对决策路径之间的相似度进行度量,因此需要对路径之间的离给予定义,定义如下:
 其中,θ(l)代表了一条决策路径中,涉及到特征 fm split point 的最小值,θ(u)代表了决策路径中,涉及到特征 fm split point 的最大值
其中,θ(l)代表了一条决策路径中,涉及到特征 fm split point 的最小值,θ(u)代表了决策路径中,涉及到特征 fm split point 的最大值
评估
评估的过程包含了 2 个具体运用场景和一个定性的 Use Study.
2 个具体的运用场景所用的数据集为:Titanic shipwreck Dataset 以及 German Credit Data
以 Titanic shipwreck Dataset 为例进行说明。
具体图示如最开始的系统图。
加载数据之后,发现主要的特征为:Sex,Title,Fare,PClass,Age 和 Family Size.
在图 B 中可以发现,Sex 是对最后预测结果最相关的特征,当 Sex=0(即女性)更容易被获救。
除了类别特征,观察数值特征,如 Fare 和 Age。对比图中 b1 和 b2,可以发现,Fare 特征,随机森林模型在 x 轴最开始的时候,split point 比较密集,说明她在寻找一个比较小的阈值,该阈值对最后的预测结果有着比较大的影响。反之,Age 上并没有该现象。
进一步观察 Fare 和预测结果之间的关系,在图 b3 中我们可以看出,pdp 曲线中在值为 25 左右处,有一个陡峭的跃升,这可以看成是随机森林模型所寻找的阈值。通过图中的交互信息(hover)可以发现,Fare>25 通常为头等舱乘客,他们往往比 Fare<25 的次级舱乘客要容易获救。
在 A 图中,聚类 a2 和 a3 的结果都为深红色,代表模型很有信心他们不会被获救。观察其具体值,发现这些点主要是来自三等舱的男性。除了 a2 聚类点,在聚类 a1 中,可以发现 6 个亮黄色的异常点。这些异常点同样是三等舱的男性但是其 Fare 为 56.为了检测模型是否在这 6 个点上有着正确的结果,通过 TN 发现这 6 个点的结果为 FN,即他们是被获救了。
为了分析,模型判断错误的原因,可以选择其中一个点进行分析,例如选取(ID=664)的乘客。c2 表明,除了大多数的红点给了负面结果之外,还有部分蓝点给了正面结果。我们可以各自选取部分点,进行对比分析,如 c1、c2 和 c3 所示。可以发现,给予负面结果的路径主要评估标准为 Sex 和 Class 而正面结果的决策路径的评估标准主要为 Fare,而这些点有着很高的值。除此之外,可以发现大多数给予负面结果的路径用 3 作为 Family Size 的阈值,而给你正面结果的路径用 1 来作为 Family Size 的阈值,说明除了特征类型,两个不同组中的决策路径在相同的特这中,选取了不同的阈值。
定性 Use Study
10 participants(7males, aged21-28)
4:information visualization
2:machine learning(no random forests)
times: 45minutes
Tutorial :Titanic dataset
Task : German Credit dataset with 10 tasks
Feedback: 12 questions(7-point Likert scale)
该系统得到的反馈为一致好评。
总结
- 该交互系统有着一定的泛化能力,比如可以用于 boosting Tree、多分类结果的随机森林模型和其他类似的树形模型等等,但是不好用于模型调参。
- 同时,该系统可以支持一定量的数据量,但当数据过大时会出现视觉混淆,屏幕尺寸受限的情况。
- 最后,使用该系统的分析人员需要一定的学习时间才能比较好的掌握该系统的使用方法和其代表的具体意义。
✉️ zexianchen@zju.edu.cn